BenchFlow builds the environments AI agents learn in.
A frontier environment lab for AI agents. We ship SkillsBench, ClawsBench, and the BenchFlow runtime.
What we ship
 01· Benchmark
01· BenchmarkSkillsBench
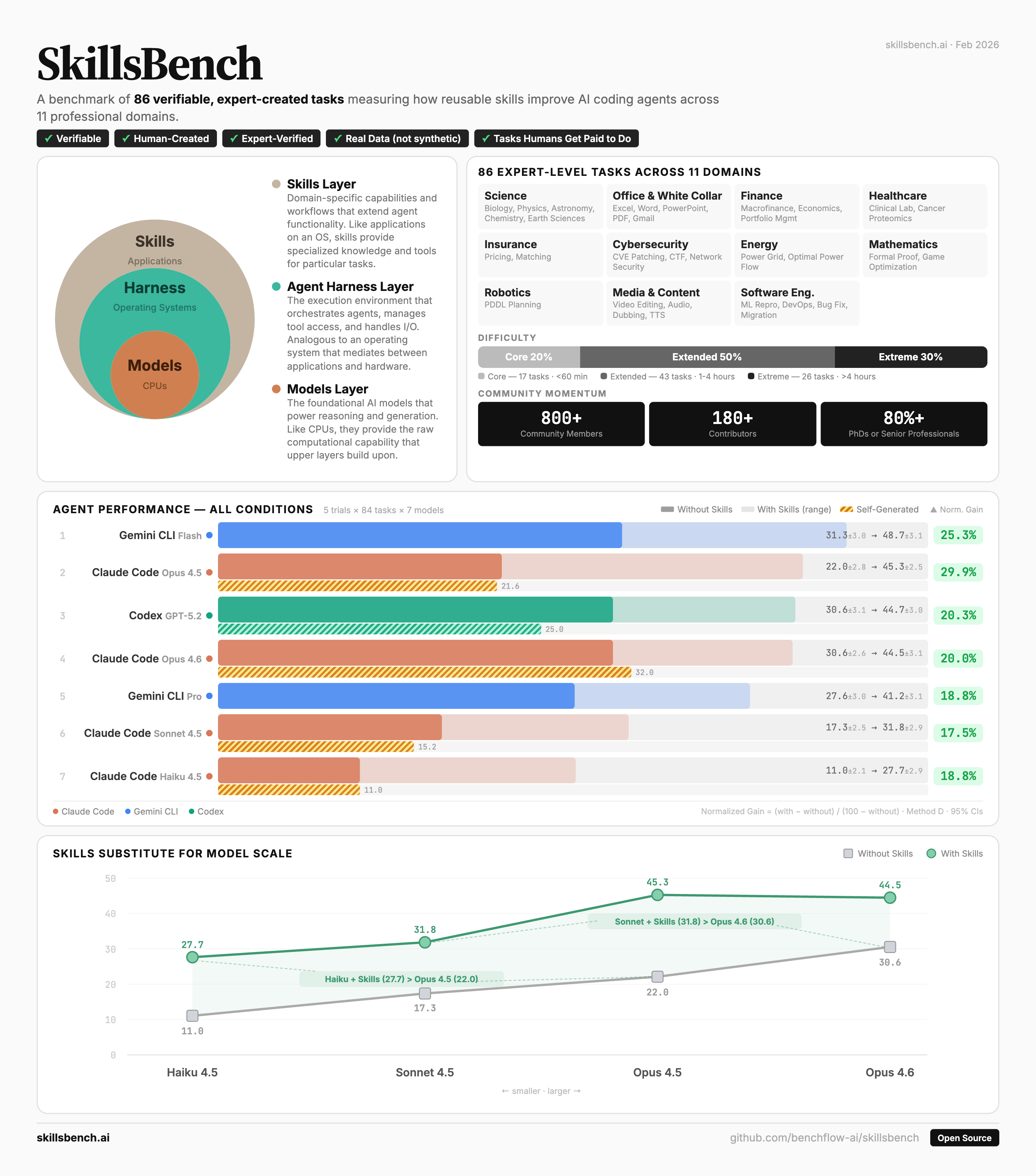
The first benchmark for whether procedural skills — instructions, scripts, references an agent loads on demand — make agents better at real work. 86 tasks, 11 domains.
 02· Environment
02· EnvironmentClawsBench
Five mock workplaces — Gmail, Calendar, Drive, Docs, Slack — wire-compatible with the upstream `gws` and Slack APIs. Production agents and skills run unchanged against a safety-evaluable replica.
 03· Runtime
03· RuntimeBenchFlow
The agent simulation runtime. One Scene-based lifecycle for single-agent, multi-agent, and multi-round evals. Sandboxed, hardened against reward hacking, full trajectory capture.
Thesis
Data is the bottleneck. Environments are the new data.
AI data went from labels to post-training trajectories to environments. Models in 2026 don’t get better from more static prompts — they get better from running through realistic environments and being judged on the whole workflow.
- 1.0
Labels
Image tags, span annotations, yes/no labels.
- 2.0
Post-training
SFT, preferences, reward labels, short trajectories.
- 3.0we’re here
Environments
Stateful workplaces with services, files, tools, verifiers, replay.
Ecosystem
- May 26· CAIS · San Jose
Agent Skills ’26 workshop
First workshop on agent skills. Speakers: Dawn Song, Ross Taylor, Kanav Garg (DeepMind), Yu Su. Live SkillsBench design challenge.
agentskills-workshop.org ↗ - May 27· San Francisco
SkillsBench 1.0 Launch party
Presented by Google DeepMind — the afterparty to the CAIS workshop. We announced SkillsBench 1.0: 100+ expert-curated tasks, built with Kaggle. Talks from Xiangyi Li, Wenbo Chen, Han Lee, and Kaggle.