/
BIRD-critiqBadge

BIRD-Critic 1.0 introduces a novel SQL benchmark designed to evaluate a key capability: Can large language models (LLMs) diagnose and solve user issues within real-world database environments?
The benchmark comprises 600 tasks for development and 200 held-out out-of-distribution (OOD) tests. BIRD-CRITIC 1.0 is built on realistic user issues across 4 prominent open-source SQL dialects: MySQL, PostgreSQL, SQL Server, and Oracle. It expands beyond simple SELECT queries to cover a wider range of SQL operations, reflecting actual application scenarios. Finally, an optimized execution-based evaluation environment is included for rigorous and efficient validation.
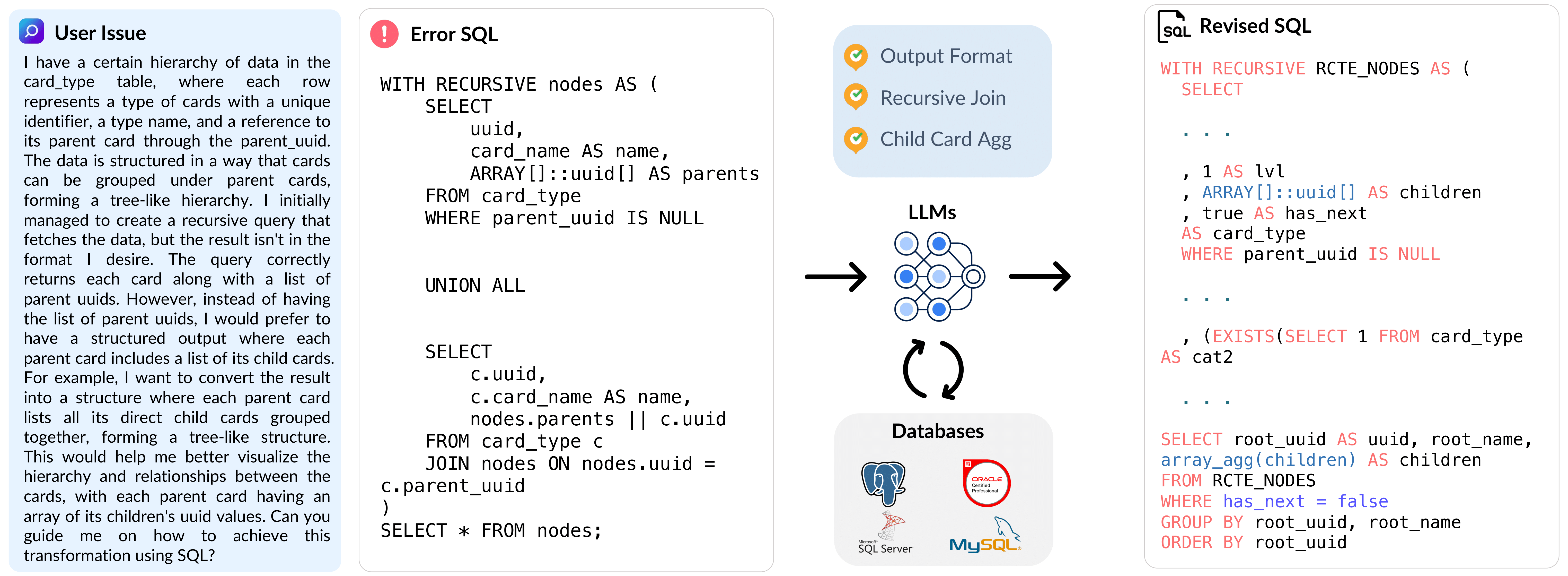
Each task in BIRD-CRITIC has been verified by human experts on the following dimensions:
We are releasing a lite version of BIRD-Critic, bird-critic-1.0-flash-exp, which includes 200 high-quality user issues on PostgreSQL when developing real-world applications. We curate tasks by:
| Rank | Model Name | Score | Level |
|---|---|---|---|
| 1 | o1-preview-2024-09-12 | 38.5 | 🏆 Leading |
| 2 | deepseek-reasoner (r1) | 34.0 | 🌟 Elite |
| 3 | claude-3-5-sonnet | 24.0 | 🔸 Advanced |
| 4 | gemini-2.0-flash-exp | 24.0 | 🔸 Advanced |
| 5 | Qwen2.5-Coder-32B-Instruct | 23.5 | 🔸 Advanced |
| 6 | gemini-2.0-flash-thinking-exp | 19.5 | 🔸 Advanced |
More results can be found here
The BIRD-CRITIC 1.0 benchmark is available in the following configurations:
bird-critic-1.0-flash-exp: A lite version consisting of 200 instances on PostgreSQL.bird-critic-1.0-open: The full version containing 600 instances across MySQL, PostgreSQL, SQL Server, and Oracle.bird-critic-1.0-postgresql: A 600-instance version specifically for PostgreSQL.bird-critic-1.0-bigquery: A lite version containing between 100 and 200 instances for BigQuery.db_id: The name of the database.query: The user query is rewritten in the BIRD environment.error_sql: The buggy SQL query written by the user.sol_sql: The ground truth SQL solution.preprocess_sql: SQL queries to run before executing the solution or prediction.clean_up_sql: SQL queries to run after the test cases to revert any changes made to the database.test_cases: A set of test cases to validate the predicted corrected SQL.efficiency: True if this question needs optimization, measure the cost by Query Execution Plan (QEP)external_data: For the external JSON data if present./baseline directory../evaluation directory.To avoid data leakage by auto-crawling, we do not include GT solution sqls and test cases along with data. please email bird.bench23@gmail.com or bird.bench25@gmail.com for full set, which will be sent automatically.
from datasets import load_dataset
dataset = load_dataset("birdsql/bird-critic-1.0-flash-exp")
print(dataset["flash"][0])
To run the baseline code you need to install the following dependencies:
conda create -n bird_critic python=3.10 -y
conda activate bird_critic
pip install -r requirements.txt
You also need to setup the model name (eg., gpt-4o-2024-08-06) with the API key in the config.py file. Then you can run the following command to generate the output:
# Generate the prompt
cd baseline/run
bash generate_prompt.sh
# LLM Inference, need to set the API key in config.py
bash run_baseline.sh
The output will be save in the ./baseline/outputs/final_output/
We use docker to provide a consistent environment for running the benchmark. To set up the environment, follow these steps:
./evaluation named with postgre_table_dumpscd evaluation
docker compose up --build
perform_query_on_postgresql_databases() function in the evaluation/src/db_utils.py file to interact with the PostgreSQL database. query is the SQL query you want to run, and db_name is the name of the database you want to run the query on. The function will return the result of the query.docker compose exec so_eval_env bash
cd run
bash run_eval.sh
The output will be save in the ./evaluation/outputs/
If you want the log file for each instance, you can set the --logging to true in the run_eval.sh script.
BIRD Team & Google Cloud
Information
Organization
xiangyi-li